Reimagine growth at Elevate – Dallas 2025. See the Agenda.
Who We Serve
We strengthen bold leaders – from the world’s largest companies to ambitious disruptors – helping them outpace the competition and shape the future.
What We Offer
Our memberships, custom support, and in-depth published research equip you with the reliable information you need to make data-led decisions with measurable success.
Our Expertise
We blend deep industry expertise with leading-edge research driving growth, innovation, and resilience. With Everest Group, data meets strategy, and vision turns into measurable impact.
Insights
Our wealth of resources inspires ideas and new ways of thinking with real-world solutions and the latest trends that drive your business forward.
Company
We’re committed to helping you get it right. Through trusted expertise, rigorous research, and practical insights, we enable businesses to make confident decisions.
Filter
Displaying 1-10 of 12
The Rise of Machine Learning Operations: How MLOps Can Become the Backbone of AI-enabled Enterprises | Blog
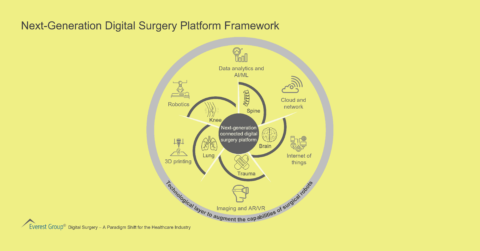
Next-Generation Digital Surgery Platform Framework | Market Insights™
Federated Learning: Privacy by Design for Machine Learning | Blog
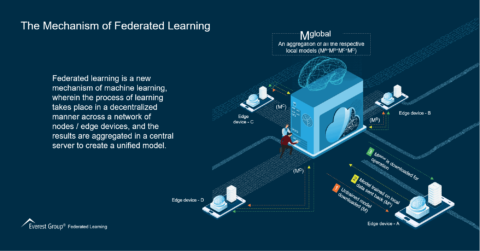
The Mechanism of Federated Learning | Market Insights™
Comparing Centralized and Federated Learning | Market Insights™
Recharge Your AI initiatives with MLOps: Start Experimenting Now | Blog
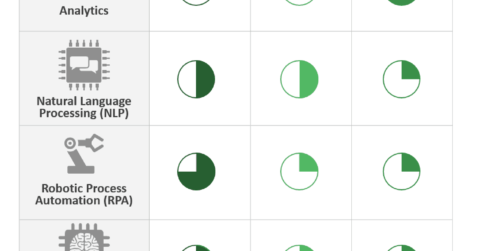
Key Technologies That Form Underlying Systems for Smart RPA Solutions | Market Insights™
Impact Potential of Next-generation Technologies in Talent Acquisition | Market Insights™
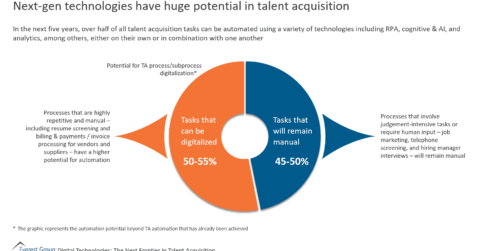
Next-Gen Technologies Have Huge Potential in Talent Acquisition | Market Insights™
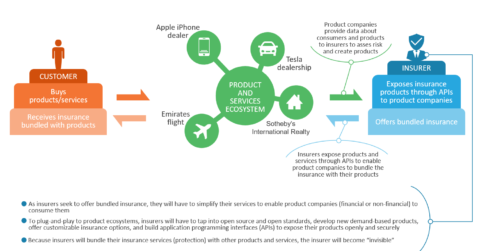
Insurer of the Future: Invisible Protection Provider | Market Insights™