Who We Serve
We strengthen bold leaders – from the world’s largest companies to ambitious disruptors – helping them outpace the competition and shape the future.
What We Offer
Our memberships, custom support, and in-depth published research equip you with the reliable information you need to make data-led decisions with measurable success.
Our Expertise
We blend deep industry expertise with leading-edge research driving growth, innovation, and resilience. With Everest Group, data meets strategy, and vision turns into measurable impact.
Insights
Our wealth of resources inspires ideas and new ways of thinking with real-world solutions and the latest trends that drive your business forward.
Company
We’re committed to helping you get it right. Through trusted expertise, rigorous research, and practical insights, we enable businesses to make confident decisions.
Filter
Displaying 1-9 of 9
The Ultimate Guide to AI Agents in Cybersecurity: Innovations, Investments, and Future Trends | Blog
Unlocking the Potential of Sensitive Data with Data Clean Rooms | Blog
Demystifying Data Security – A Comprehensive Guide to Data Security | Blog
Self-aware Data – Securing Data across its Life Cycle | Blog
Top Retail Digital Investment Strategies | Market Insights™
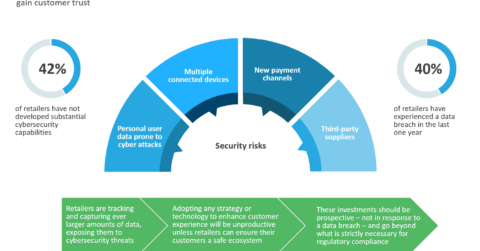
Retailers Leaving Themselves Unprotected from Cyber Attack | Market Insights™
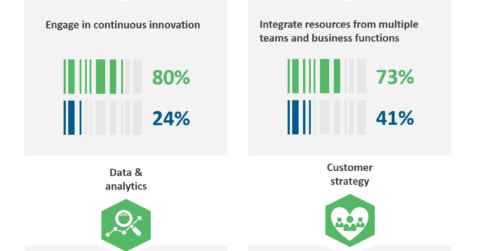
Retail Digital Pinnacle Enterprises™ Investment Pyramid | Market Insights™
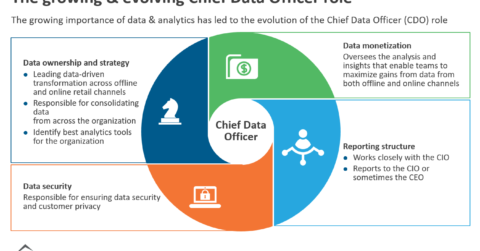
The Growing & Evolving Chief Data Officer Role |
Digital Retail Pinnacle Enterprises™ Differentiators | Market Insights™