Blog
Context engineering – key to agentic success in enterprises
As enterprises race to build their universes of sophisticated generative AI (gen AI) models and agentic solutions, the first instinct was predictable: strengthen the data foundation. The first wave of readiness was all about modernization – platforms, pipelines, vector databases – making sure Artificial Intelligence (AI) systems had enough structured fuel to run and scale. Then came the second layer of defence with governance. Enterprises started doubling down on control, embedding trust, security, and compliance into their data ecosystems.
In 2026, both layers have become table stakes. Tech providers are positioning themselves as AI-ready data platforms, service providers are acting as trusted advisors for the transformation and yet, something still does not click. Agents can assist, but they rarely act with real autonomy. They generate, recommend, and respond, but they do not consistently think or decide the way humans do. Despite the advancements in model intelligence and agentic capabilities, most enterprises who are ahead in the AI journey are still operating in what can best be described as the “assisted intelligence” phase.
Reach out to discuss this topic in depth.
The gap from assisted to autonomous is not a data foundation or a governance problem. To act with autonomy, agents need to understand how work gets done. That logic rarely sits neatly inside systems. Instead, it lives in hallway conversations, tacit knowledge, business exceptions, and unwritten rules, because that is how businesses function in the real world. Capturing and operationalizing this is where the next layer of differentiation begins to emerge: the context engineering layer.
Context engineering is quickly becoming one of the most talked-about ideas in enterprise AI adoption, amplified by investor narratives, emerging startups, and a surge in industry chatter.
Exhibit 1: Mentions of the “context layer” spiked sharply post Foundation Capital’s Context Graphs thesis, signaling a rapid shift from niche concept to mainstream discourse

In a world where intelligence itself is becoming commoditized, where enterprises increasingly rely on the same frontier models and similar agentic capabilities, advantage no longer comes from the model alone, but from what surrounds it. Context engineering is becoming the new competitive edge as it enables agentic systems to think the way a business operates, grounded in institutional knowledge, domain nuances, decision logic, and the subtle realities that shape everyday work.
And while the industry is still debating what “context engineering” truly means, the more pressing need is to cut through the noise and answer a few fundamental questions:
- How is the context engineering layer structured?
- What does it look like in practice?
- Who owns it, and who is building it today?
- Where does the context engineering sit within the enterprise stack?
- Is context engineering purely a technology construct, or also a services play?
How should the context engineering layer be structured?
Strip away the buzzwords, and context engineering comes down to one thing: making enterprise AI decisions reliable, explainable, and scalable. It does this by tightly coupling two worlds that have long remained disconnected, business logic and operational infrastructure, largely because business logic was never truly codified. In doing so, it attempts to connect what the enterprise knows with how the enterprise acts.
The structure becomes clearer when viewed across two phases of action: Knowledge and Decisions.
Exhibit 2: The context engineering layer bridges fragmented business logic and operational infrastructure, connecting how enterprises define meaning with how decisions are executed at scale

Operational infrastructure includes graphs, embeddings, metadata systems, retrieval mechanisms, decision traces, and orchestration frameworks. Together, these capabilities make context usable at scale by enabling how it is stored, retrieved, and executed, and as a result, this layer is relatively more mature.
Business logic, on the other hand, includes taxonomies, definitions, constraints, policies, and approval criteria. It defines meaning and how decisions are made, yet this layer remains fragmented and inconsistently captured across the enterprise.
The context engineering layer will link the operational infrastructure with the business logic to make decisions explicit, consistent, and executable by AI agents at scale.
What does a context engineering layer actually look like?
In practice, the context engineering layer is not a one-and-done pipeline. It is a system that continuously translates fragmented knowledge and formalizes business logic into decisions the enterprise can trust and scale. It sits between raw data and business action, ensuring that what flows into AI agents is not just information, but meaning.
Exhibit 3: Context engineering turns data into decisions through a continuous evaluation and feedback loop
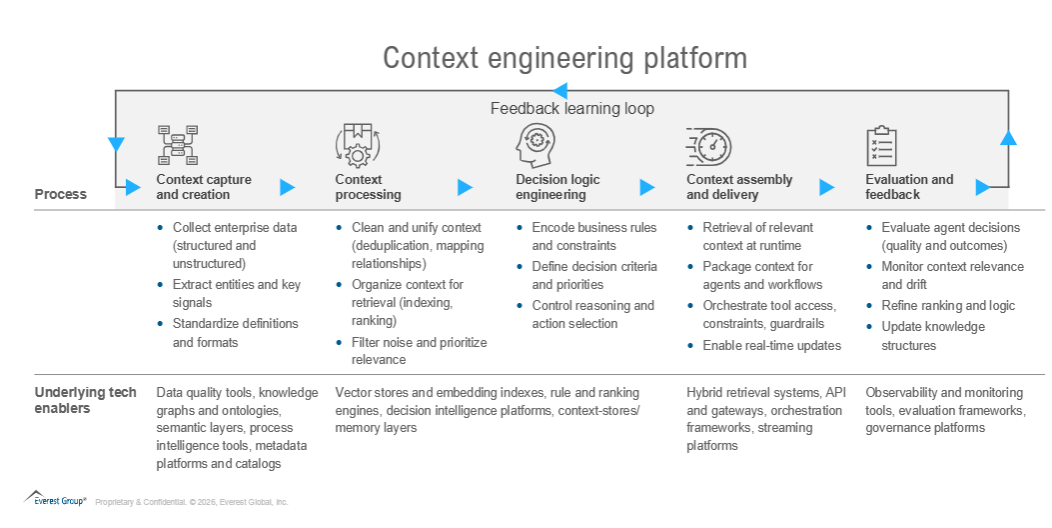
Most enterprises already have the context creation pieces, but what they lack is integration at the level of meaning. Context can no longer be static or embedded within systems. It has to be dynamically constructed, retrieved, and applied in real time. Decisions cannot be one-off outcomes, but part of a continuous loop where every action refines the underlying context.
The difference is subtle but consequential: treat context as only infrastructure, and you improve efficiency. Treat it as a strategic layer, and you improve decisions.
Context vs Control: Who owns the context engineering layer?
Today, the components of context engineering are scattered across platforms, tools, workflows, and applications, making cohesive integration and orchestration critical. But this fragmentation also creates a deeper issue of ownership. When context exists only in fragments, it loses coherence and no single player consistently owns the full context-to-decision flow end-to-end.
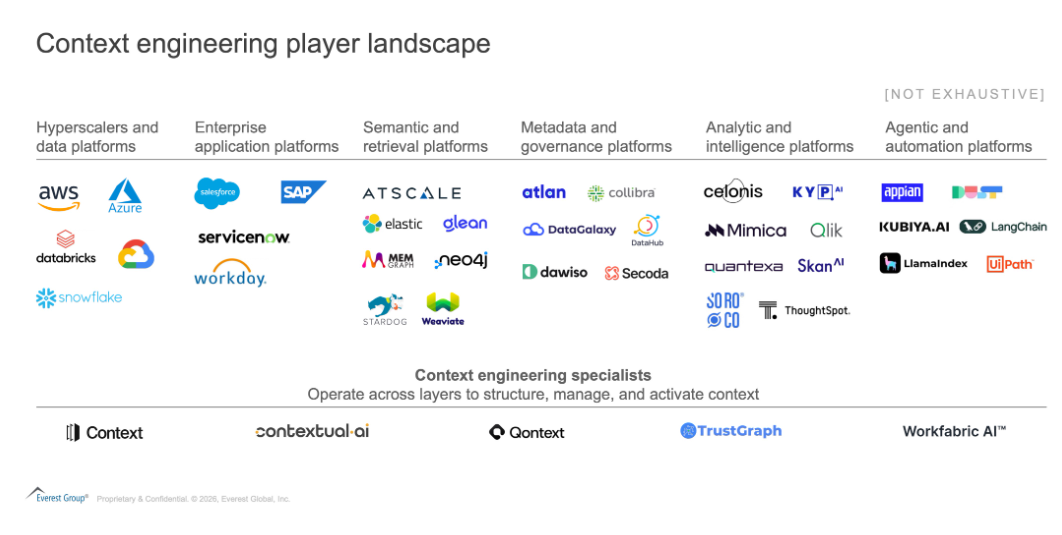
The context engineering provider landscape is crowded, but the intent is consistent. Every player is moving toward ownership from a different starting point, often managing pieces of context, but rarely the entire lifecycle:
- Hyperscalers and data platforms are embedding early notions of context engineering into their ecosystems, tying it to compute, storage, and data pipelines, though their core remains infrastructure-first
- Governance and metadata platforms are beginning to move upstream, evolving catalogs into systems that attempt to capture meaning and enforce policy, but are still largely rooted in compliance and control
- Semantic and retrieval platforms focus on structuring relationships and enabling context-aware retrieval, forming the backbone of how meaning is connected and accessed
- Analytics and intelligence platforms such as Business Intelligence (BI) and analytics, process intelligence, and decision intelligence systems, bring context closer to where it is consumed by translating data into insights and decisions, but have limited influence over how that context is originally defined, structured, and made reusable across the enterprise.
- Enterprise application platforms such as Enterprise Resource Planning (ERP) and Customer Relationship Management (CRM) systems continue to control where decisions are ultimately executed, making them critical gatekeepers in the stack, though their influence is typically limited within their own application boundaries
- Agentic AI and automation platforms orchestrate actions using context at runtime, but largely depend on external systems to supply structured, reliable context
- Context-engineering specialists are building from the ground up, agent-first, tightly coupled context engineering systems that aim to unify context, reasoning, and execution, though the space remains early and unproven
Exhibit 4: The context layer battleground, a fragmented race for ownership, with multiple contenders but no end-to-end leader yet
The real opportunity lies in the gap between those who build context and those who control decisions. Today, these responsibilities sit with different players, some focus on structuring and managing context, while others govern how it is applied within decision flows. Bridging this divide is where the next layer of enterprise value will be created.
This whitespace is already attracting a new wave of context engineering-native startup players such as Workfabric.ai, Contextual.ai, Qontext.ai, Nozomio, and TrustGraph, that are focused on making context more structured, accessible, and usable within AI. However, unless they can embed deeply within decision workflows and overcome enterprise constraints around integration, trust, and scale, they risk remaining enablers. Helping others make better decisions, but not owning the outcomes or the value created.
Ultimately, ownership of the context engineering layer will not be defined by who organizes information, but by who controls how decisions are made and where that control sits in the enterprise stack.
Where will the context engineering layer live?
This naturally leads to the next question: if no single player owns the context engineering layer today, where will it actually reside? At the heart of this is a structural tension. Will context engineering be embedded within existing platforms, or will it emerge as an independent control layer that sits across them?
We see two models taking shape.
In the first, context engineering capabilities are embedded within existing data and platform ecosystems, evolving as an extension of current infrastructure. This approach enables faster adoption, tighter integration and alignment with existing data and AI workflows. However, it also risks reinforcing fragmentation as each platform builds its own version of context engineering, limiting cross-system consistency and increasing vendor lock-in.
In the second, context engineering emerges as an independent cross-platform layer responsible for orchestrating meaning and decision-making at scale. This elevates context engineering to a strategic, enterprise-wide capability and enables greater consistency across domains. However, it introduces significant integration complexity, potential overlap with existing platform capabilities, and persistent questions around ownership and control.
In reality, the evolution is unlikely to be binary. Most enterprises will move through a phased path – starting with use-case-led implementations of context engineering, expanding toward domain-level consolidation to standardize meaning, and gradually converging toward a more unified, enterprise-wide layer that can support cross-domain, agent-driven decisions.
Is the context engineering layer a technology play or a services game?
If no single platform owns the context engineering layer today, who will actually build, integrate, and operate it? It is tempting to frame context engineering as a product problem. But it is not something that can simply be installed. It must be defined, operationalized, and continuously refined in line with how the business evolves.
At the same time, it is not purely a services problem either. Platforms are rapidly embedding context engineering capabilities into their ecosystems, through metadata layers, governance frameworks, semantic models and AI tooling. However, these capabilities remain inherently bound by platform-specific architectures, limiting their ability to operate consistently across systems.
The bigger challenge lies in alignment. Context engineering requires standardizing meaning, codifying decision logic, and orchestrating both across fragmented data, AI, and application landscapes. These systems were never designed to work together, and context engineering does not emerge automatically from tools, it must be deliberately constructed and managed across layers.
This is giving rise to a new set of services focused on context engineering capabilities such as ontology and taxonomy design, semantic modeling, metadata grounding, cross-platform orchestration, and decision logic engineering. These services are still emerging, but they point to a broader shift, from implementing systems to shaping how decisions are defined and executed.
Over time, this could evolve into a new class of managed services where providers operate and continuously govern, refine, and operationalize context engineering layers as the business conditions change. However, it remains to be seen how far this model will scale, and whether service providers can move beyond enabling context engineering to actually operating it end-to-end.
At the same time, technology providers are unlikely to cede this layer. As platforms expand their built-in capabilities, context engineering is emerging as a point of convergence and contention between platforms embedding it and service providers orchestrating it across systems.
The bottom line
Building a context engineering layer is quickly becoming a prerequisite for enterprise AI but how it is designed and operationalized will determine the value it creates. Organizations that get it right won’t just scale AI faster, they will decide better.
At the same time, context engineering is still a nascent capability, with many more things to think about. For example, what does “good” context engineering look like in practice, how its quality can be defined and sustained, and how it scales from isolated use cases to cross-domain decisioning.
If you’re thinking about these questions or exploring how to build and own your context engineering layer, we’d be glad to exchange perspectives.
If you enjoyed this blog, check out, The Ultimate Guide to AI Agents in Cybersecurity: Innovations, Investments, and Future Trends | Blog – Everest Group Research Portal, which delves deeper into another topic relating to AI.
Please feel free to reach out to Amardeep Modi, Vice President ([email protected]), Mansi Gupta, Practice Director ([email protected]) and Ishi Thakur, Senior Analyst ([email protected]) at Everest Group.